Every fix Command proposes carries a success criterion committed to git before the fix is allowed to run. The first real one went in this morning: my ShopForge repo has 10 Claude Code sessions sitting open, six of them stale work from mid-May, four of them phantoms that Command’s own status probes created. The proposed fix is a session-hygiene rule in ShopForge’s CLAUDE.md plus actually closing the six stale sessions, and the registered criterion says the open-session count must drop by at least 4 within about 25 hours, measured by deterministic code, with the four phantoms required to stay exactly 4 on both sides. If the count doesn’t move, the recorded verdict is “didn’t move,” and a second attempt requires a new, recorded registration.
That obligation is a design decision, not a result. Command is nine days into its current shape and most of what it exists to prove is still ahead of it, so this post is about the decisions instead: what Command is, the choices that shaped it, why I made them, and what I want to see from it in the next few weeks.
What Command is
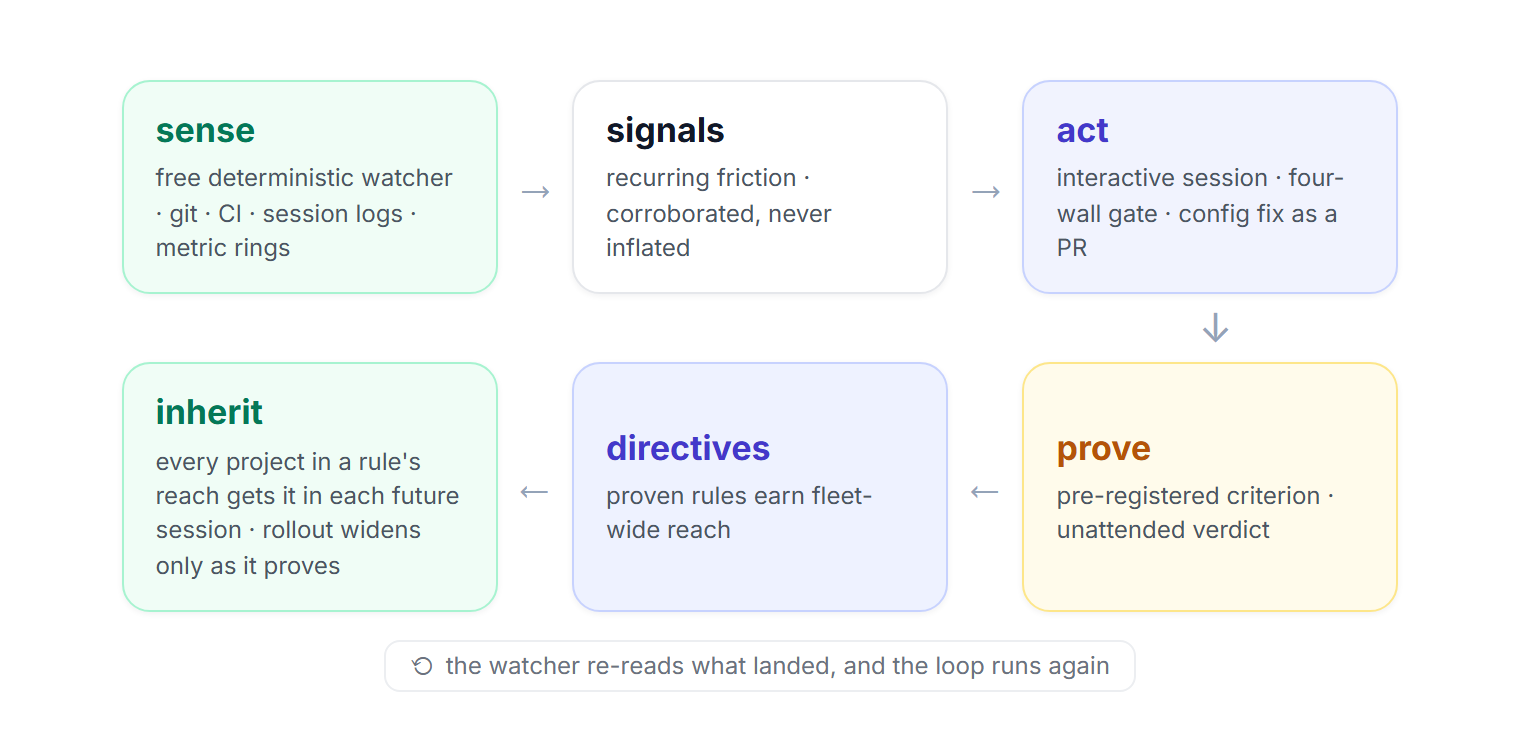
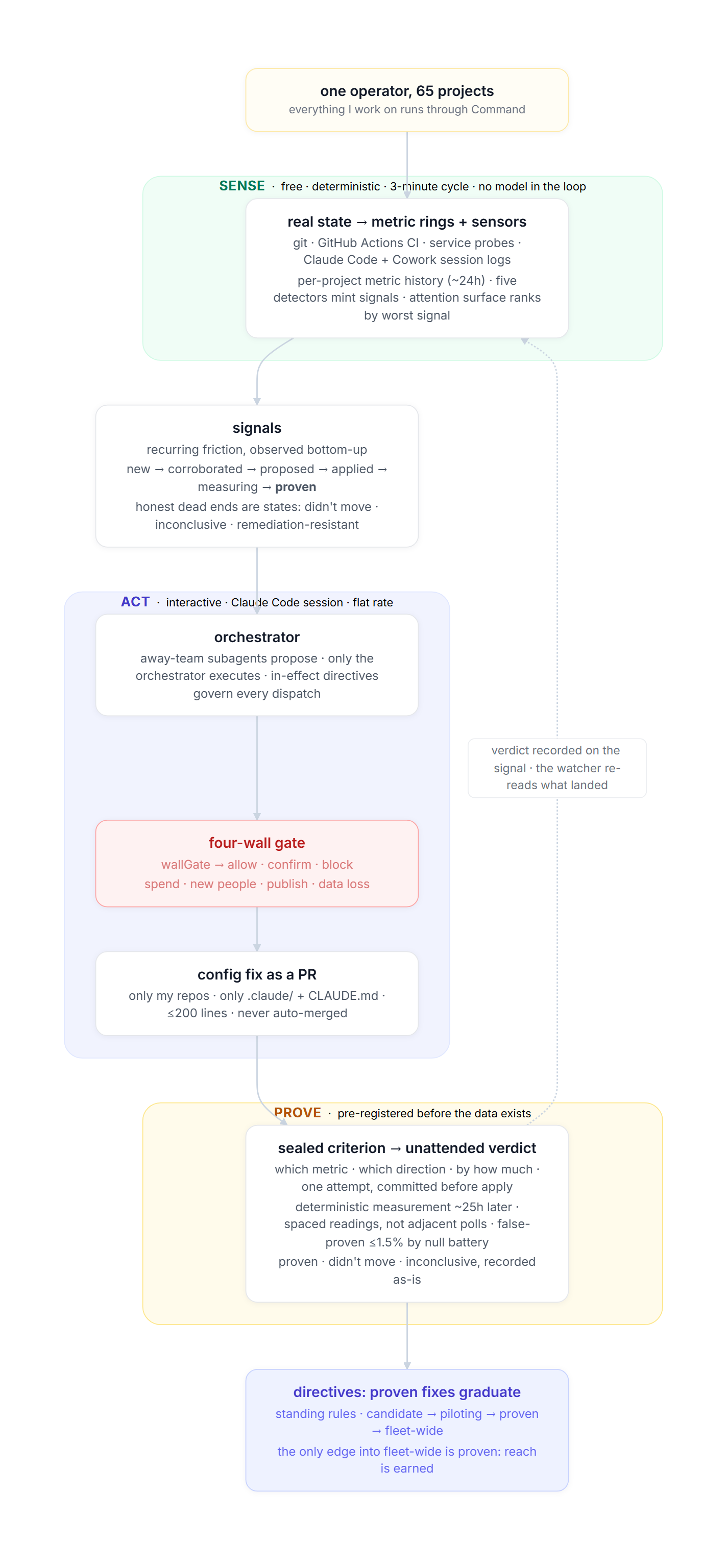
Command is the operator I run my 65 local projects through, built on Claude Code. The skeleton is a deterministic watcher plus an approval-gated orchestrator. Since early June, the job running on that skeleton is a signal engine: read the fleet’s chat logs, git state, and CI; distill them into signals about recurring friction; propose fixes to each project’s Claude Code configuration; and measure whether each fix moved a real number before recording it as proven.
The watcher is deterministic code on a three-minute cycle. It reads git status, GitHub Actions, service probes, and the session trail Claude Code and Cowork leave behind, ranks every project by its worst current signal, and keeps an attention surface current. It also feeds a per-project metric history (a ring of readings about 24 hours deep) and runs five deterministic sensors that mint signals when a condition crosses a line. The orchestrator is the interactive Claude Code session I open with command-start; it is the only part that reasons and the only part that executes gated actions.
Three kinds of durable state sit between the two halves:
- Objectives: outcomes I hand it (“land the ShopForge rebuild and drive it to a day-30 verdict”), each with an autonomy dial and living state that survives across sessions.
- Signals: recurring friction observed bottom-up. Lifecycle:
new → corroborated → proposed → applied → measuring → proven → retired, withdidn't move,inconclusive, andremediation-resistant(three failed attempts) as recorded dead ends. - Directives: standing rules rolled out top-down. Lifecycle:
candidate → piloting (1–2 projects) → proven → fleet-wide. The only edge into fleet-wide isproven → fleet-wide.
The two couple: a violation of an in-effect directive emits a signal, and a recurring proven signal can be promoted to a candidate directive, which walks the same pilot-and-prove rollout. In-effect directives are injected into every piece of work the orchestrator dispatches.
The rest of this post is the six decisions that produced that shape.
Keep the model out of the watching half
The watching half (ranking, alerting, sensing, measuring) runs with no language model in the loop. One bounded Haiku call writes each project’s status prose; it has no decision role.
Two reasons. The first is cost structure: effective June 15, 2026, Anthropic meters programmatic usage (claude -p, the Agent SDK, GitHub Actions) separately from the flat subscription, while interactive Claude Code stays on the plan. Command v1 was a long-lived SDK service, squarely in the metered bucket. Anything that runs every three minutes forever has to be free, so the continuous half became deterministic code and the reasoning moved into the interactive session I open myself.
The second is trust: a ranking I can read the code for never has an off day. Deciding which project needs me turned out to need no model at all. Only deciding what to do about it does.
Author per-repo config, don’t load it
When Command works on one of my repos, that repo’s CLAUDE.md and .claude/ directory are deliberately not loaded: settingSources: [], so an untrusted repo can’t inject instructions into the agent operating on it. A research pass found that most coding agents auto-load repo-resident instructions with no trust check, and that the gap has been exploited in the wild [research over primary sources, not my measurement].
The safe choice had a cost: Command got none of the value of per-repo config, and recovering that fidelity required exactly the SDK machinery the billing change priced out. The resolution was to invert the dependency. Command stopped consuming per-repo configuration and started authoring it: observe the fleet, find the friction, and propose the CLAUDE.md rule, skill, or hook that would have prevented it, as a reviewable PR into the target repo. The config surface stopped being an input problem and became the product.
This is also where the project’s founding claim lives: one operator means teaching it once improves every project at once. Authored config makes that mechanical. A fix lands in a repo as a reviewed PR, a fix that keeps proving out can be promoted into a directive, and a directive that survives its pilot earns fleet-wide reach. The compounding no longer depends on me remembering to route a correction into the right file.
No engine until the evals passed
Before any engine code existed, the build had to pass five go/no-go gates, each pre-registered the same way as the ShopForge case: metric and bar written down before the test ran. The reasoning: a self-improvement engine’s native failure mode is self-delusion, proposing fixes that sound right and claiming credit nothing verifies. I wanted the evidence that the engine’s proposals would have been right before building the engine, so the gates were built first and the engine had to earn its way through them.
Gate 3 was the hard one, a backtest: rewind to a date T, let the engine read only chat history from before T, have it predict which frictions to fix, and grade the predictions against what actually happened after T. It failed for four sessions straight, and the failure taught the design more than the eventual pass did. The first honest run scored P@10 = 0.30 (the fraction of the top ten proposals that proved out) against a 0.5 bar, and a multi-run pilot showed the early passing runs had been lucky draws [measured, 30 agents, 2.2M tokens]. The problem turned out to be the metric, not the engine: on a repo where only a handful of surfaced frictions ever recur, P@10 has a structural ceiling of min(recurring, 10)/10, and on the failing repos that ceiling sat below the bar. The gate was unpassable by construction.
The correction followed the rules: re-specify to P@5 plus NDCG@5 (a rank-quality score) to match the actual product surface, commit the new bars before touching held-out data, then run. Held-out results on code repos: chat-arch 0.84/0.86, dropKnowledge 0.72/0.79 [measured, Phase-0 gate board]. My website repo failed at 0.16 to 0.28, so non-code repos are out of scope rather than softened. The confirmatory base is two repos, and the strict automated gate still prints NO-GO over one exploratory near-miss; the GO is a recorded judgment call. All of that stays in the records.
Two design consequences came out of the failure. The eval plan now carries a standing instrument-validity audit (ceiling check, denominator check, operating-point sweep, run-variance check) that runs before any gate verdict gets trusted. And one incidental find: Claude Code’s default cleanupPeriodDays: 30 had been silently deleting my transcripts, the engine’s raw material, the entire time. Mine is now 3650; if you rely on your logs for anything, check yours.
Every grader proves its error rate on noise first
The engine grades its own fixes, so the question behind every measurement path is the same: how often does this grader lie? The design rule is that no measurement path judges a real fix until it has demonstrated its false-positive rate on synthetic no-effect data.
That rule has already paid for itself. The watcher’s readings arrive every three minutes, which makes consecutive readings autocorrelated rather than independent; fed naively into a before/after comparison, “proven” fires constantly. On synthetic no-effect series, naive consecutive-poll windows false-prove 37 to 42 percent of the time [measured, null battery]. The recipe that shipped instead (twelve readings spaced at least two hours apart, one-hour settle) holds false-proven at or under 1.5 percent with at least 99 percent detection across its certified range [measured, verify-derived-measure.ts].
The same rule decides what the system refuses to do. Two production metrics turned out stickier than anything in the certified envelope (lag-1 autocorrelation around 0.99); extending the certification was tried and measured failing at 5 to 10.5 percent false-proven, so those metrics require a pre-registered absolute floor instead, with the floor committed before the data exists, and the floor protocol carries its own certification (false-proven 0.0 percent, detection 91 to 94 percent on case-matched noise [measured, M1 pre-registration]). Even the ranking learns under a null: fitting rank weights to my confirm and dismiss decisions produces a positive out-of-sample “improvement” on roughly a quarter of pure-noise datasets, so a fitted profile must beat the noise distribution’s 95th percentile before it is even proposed.
Narrow applies, earned reach
The apply step is deliberately small: a pull request, only into repos I own, touching only .claude/ paths and CLAUDE.md, capped at 200 changed lines, on a fresh branch, never auto-merged. Global ~/.claude changes are snapshotted and reversible. I merge or I don’t.
Reach is the second half of the decision. A fix proves itself on one repo before it can become a directive; a directive pilots on one or two projects before it can go fleet-wide; the only edge into fleet-wide is proven → fleet-wide. Nothing reaches all 65 projects on a hunch, including the system’s own good ideas. The reasoning is blast-radius control: the failure I’m designing against isn’t one bad fix, it’s one plausible-but-wrong rule quietly degrading every project at once.
The review machinery around the apply step earned two findings worth recording. Multi-agent adversarial review misses things: on one PR, OpenAI’s Codex connector flagged three real findings the whole review team had missed, including a path-traversal hole in the very gate that restricts writes to .claude/ paths. Independent reviewers with different priors beat more reviewers with the same priors. And one reviewer technique worth stealing: delete the safety check a new test is supposed to protect, and if the test still passes, the test was passing for the wrong reason.
Four walls in deterministic code
No objective, no autonomy dial, and no approved plan can cross these without a separate, explicit confirmation from me:
- Spend money.
- Message a new or unknown person.
- Publish or go public.
- Irreversible data loss.
The walls are deterministic code with tests behind them, not a model’s judgment, and the signal engine gave them new customers: a remediation PR is a publish-wall action, a global config apply is a publish-wall action with a standing all-projects confirm, a worktree teardown routes through the data-loss wall. The limit that stays: once I confirm an action, it runs unsandboxed on my machine. Confirmation gates the decision, not the blast radius.
Build a starting version yourself
Command’s engine is Claude Code, so the fastest way to get something like it is to hand the spec to your own Claude Code. This prompt encodes the decisions above. The proof loop is the new part; don’t skip it.
You are helping me build a personal "operator" for my projects, on top of you (Claude Code). Build it in two parts. Ask me about any open decisions first, then build the first slice and we iterate.
PART 1, a free deterministic watcher (no LLM calls, so it costs nothing and can run in the background):
- Read a registry file listing the projects I track (path, name, optional expected service URL or port).
- On an interval (every few minutes), read each project's real state with plain commands, no model:
- git: dirty working tree, ahead or behind upstream, time since last commit.
- CI: latest GitHub Actions run conclusion, via the `gh` CLI.
- activity: whether there's a recent or open Claude Code session for the project, from the local ~/.claude logs. (First check the cleanupPeriodDays setting; the default silently deletes transcripts after 30 days.)
- Append each project's key metrics (open sessions, days dirty, commit age) to a small per-project history file each cycle.
- Raise an alert when: CI is red on the default branch, uncommitted work has gone stale, a branch is unpushed, or sessions are piling up. Rank projects deterministically by worst signal. No LLM in this layer.
PART 2, an interactive orchestrator I invoke when I sit down (build it as a Claude Code skill):
- Read the watcher's state, show me the ranked attention list, and propose ONE fix for the worst recurring friction: a rule in that repo's CLAUDE.md or .claude/ directory, as a pull request I review. Touch only .claude/ paths and CLAUDE.md, keep it under 200 changed lines, never merge it yourself.
- BEFORE applying the fix, pre-register the success criterion in a committed file: which metric should move, in which direction, by at least how much, and within what window. One attempt per registration.
- AFTER the window passes, measure from the watcher's metric history and record the verdict honestly: proven, didn't move, or inconclusive. A fix that didn't move the number is a finding, not a failure to hide. Never re-measure quietly, never adjust the floor after seeing the data.
- Before trusting any gate or metric, compute its ceiling on the actual data: can this metric even reach the bar? If not, the gate is broken, not the work.
- Warning about self-measurement: consecutive polls are autocorrelated. Compare readings spaced hours apart, not adjacent ones, or your false-positive rate will be enormous. Test your measurement code on synthetic no-effect data first and report its false-"proven" rate to me before trusting any real verdict.
- Make sure the watcher never perturbs what it measures: tag its own activity (its sessions, its probes) so it can't count itself.
THE FOUR HARD WALLS, enforced in deterministic code at the point a tool or command runs, never by your judgment. Never do any of these without a separate, explicit confirmation from me:
(a) spend money, (b) message a new or unknown person, (c) publish or go public (deploy, merge to main, post publicly), (d) cause irreversible data loss.
- Implement this as a gate function every side-effecting step passes through; it returns allow, confirm, or block. Wire it into a PreToolUse hook where the harness supports it, so the gate fires on the tool call itself instead of relying on you to remember.
- Subagents only do read-only and reversible work and PROPOSE risky steps. Only the top-level orchestrator runs a gated step.
CONSTRAINTS:
- Keep all model work in the interactive session so it stays on my flat Claude Code subscription; keep the watcher model-free.
- It runs locally and unsandboxed once I confirm a step: confirmation gates the decision, not the blast radius. Single-user.
Start with the watcher plus ONE pre-registered fix and prove the whole loop end to end, including one honest verdict, before adding anything else.After the first pass you’ll have a watcher reading real project state and an orchestrator that proposes one fix, registers what success means before applying it, and tells you the truth about whether it worked.
What I want to see next
Three tests are queued, each with a recorded definition of done.
M1: the measurement loop on one real fix. The ShopForge registration from the opening. The clock starts when I merge the rule PR; the verdict records unattended about 25 hours later (a one-hour settle, then the 24-hour window the measurement recipe needs), written by the watcher’s deterministic path with no model and no me in the loop. A “proven” certifies the loop end to end. An honest “didn’t move” or “inconclusive” also counts as the loop working. What would actually worry me is a verdict that arrives looking too good: the four phantom sessions are Command’s own contamination of its own metric, and the registration requires them to stay exactly 4 through the window, with drift in either direction, including the flattering direction, recording the attempt as inconclusive. Even the detector fix that would stop the probes creating phantoms is held until after the verdict, so a measurement correction can’t mix into the measured effect.
M2: the directive loop on reality. One standing rule walking candidate → pilot → proven → fleet-wide on real project evidence, with the proof gate firing on a real pilot signal rather than a synthetic one. M1 proves the system can grade a fix; M2 proves a graded fix can earn reach.
June 15: the billing answer. The substrate split rides on an inference: that subagents inside an interactive session bill against the flat subscription. Anthropic’s metering starts June 15 and the meter will answer it. The design holds either way; the cost story is an inference until then.
Behind those, the slower hopes. The ranking calibration has zero real labels today; I want a few weeks of confirm-and-dismiss decisions on the books, and then to see whether a fitted profile ever beats the permutation null on my actual behavior. The ShopForge rule’s preventive effect, whether pile-ups stop forming rather than getting cleaned up once, has its own recurrence watch. And the claim I most want evidence for is the founding one: proven fixes accumulating across the fleet faster than I could have routed them by hand. If fixes keep coming back “didn’t move,” the proposal engine isn’t good enough, and the proof discipline will say so in writing.
Command is nine days into this shape. The next post about it should have verdicts in it. The project page tracks its current status between posts.
Sources: Anthropic Help Center, “Use the Claude Agent SDK with your Claude plan”; Claude Code docs, “Run Claude Code programmatically”. Gate scores, false-proven rates, and the M1 protocol are from Command’s own committed eval records (Phase-0 gate board, signal-engine spec, M1 pre-registration), measured on my machine; Command’s repo is private, so they’re cited here rather than linked.
This post was rewritten on June 11, 2026. The original June 3 version described the architecture before the Fleet Signal Engine existed.